Ada 服务器管理员文档
资源管理相关
htop 使用
htop 可以方便地查看 CPU、Memory、Swap 占用,并且看到各进程/线程资源使用情况。通过鼠标点击表头,可按当前字段增序或降序排列(如点击 CPU% 将按 CPU 占用升序排列,再次点击将按降序排列)。底部有该软件操作的按键提示,可以通过键盘操作,也看通过鼠标直接点击。
在 htop 界面按 F1 可以查看使用帮助。比如,可以看到各资源占用 bar 各颜色的具体含义:

其中显示的按键中有一些我常用的功能,如:
H:隐藏/显示用户态线程(白色字体为进程,绿色字体为线程);t:以树形结构显示进程/线程间父子关系;u:只显示某一用户的进程/线程
通过 F2 可对界面进行一些配置,默认配置已够日常使用。但也可以进行一些个性化的配置,比如修改界面布局,Meters 和 Screen 分别对应于 htop 界面的上下两部分,在最左侧选中 Meters/Screen 以后可以添加/删除/重排属性。
tmpfs:
默认情况下 tmpfs(即
/tmp)会存放在内存中,并被归类为 shared memory。如果 shared memory 占用量很高,可以考虑清理/tmp目录,可在/etc/tmpfiles.d/tmp.conf中配置/tmp自动清理:上述配置表明,每次执行,系统都会删除
/tmp中 3 天未访问的文件(默认每天执行一次)。运行如下命令可立即执行删除操作:
资源限制
ada-709 作为大家的主要登录节点,若用户进程把内存占满,容易导致他人进程无响应,甚至无法登录服务器。因此,做出如下限制(主要针对内存)。
PS:由于有同学有需要使用 ada-709 所有的 CPU 核心跑实验的需求,所以未对单用户可使用的 CPU 资源进行限制,因此,若 CPU 被跑满,仍有可能导致服务器变卡。
对单用户资源限制
在文件 /etc/systemd/system/user.slice.d/override.conf 中配置如下内容:
HELP:https://www.freedesktop.org/software/systemd/man/latest/systemd.resource-control.html
若修改,使用 systemctl daemon-reload 启用配置。(若有人反应登录不上服务器,但其他人都正常,可能是因为他有进程的内存使用量达到了限制,导致 ssh 进程无响应)
对 docker 容器总体资源进行限制
若 ada-709 上有多个用户运行高负载进程,那么也可能使得 Memory 被用完,导致其他人无法登录服务器。所以也对 docker 容器总体所能使用的 Memory 进行限制。
参考资料:https://unix.stackexchange.com/questions/537645/how-to-limit-docker-total-resources/550954#550954
目前只做了如下内存限制(/etc/systemd/system/docker_limit.slice):
即,当所有 docker containers 中的内存使用量达到 50GB 时(总空间 62.6GB),限制 docker 容器中进程的执行速度,期望以此控制内存使用量。
GPU 相关
GPU 配置
为了获得稳定的测试数据,GPU 需要开启 Persistence 模式,并且锁定 GPU 频率。该配置文件位于每台服务器的 /etc/systemd/system/nvidia-persistenced.service.d/override.conf:
[Service]
ExecStartPost=/usr/bin/nvidia-smi -pm 1
ExecStartPost=/usr/bin/nvidia-smi -lgc <graphics-clock>
其中 <graphics-clock> 是要锁定的频率,这个频率不同的 GPU 值不一样,通过如下命令可查看 GPU 0 的最大频率:
而命令 nvidia-smi -i 0 -q -d SUPPORTED_CLOCKS 会列出 GPU 0 的所有可以设定的频率。
可以先通过
nvidia-smi -lgc <graphics-clock>设为最大频,然后watch -n 0.2 'nvidia-smi -q -d CLOCK | grep -A 1 " Clocks"'观察一段时间,或者上点负载持续一段时间。等频率稳定后,看频率最低的那块 GPU 最高能达到什么频率。然后把同型号的 GPU 的最高频都锁定到那个值。例如:在实验室 4090 机器上 4 张卡最高能达到的频率分别是 2790、2730、2655、2805,所以为了性能统一,将频率锁定为 2655(
nvidia-smi -lgc 2655)。
为了每次重启后配置仍然生效,需要把命令写入 /etc/systemd/system/nvidia-persistenced.service.d/override.conf,创建该文件后,需要运行如下命令生效:
sudo systemctl daemon-reload # 重载配置文件
sudo systemctl enable nvidia-persistenced.service # 设置开机自启动
sudo systemctl start nvidia-persistenced.service # 立即启动
systemctl status nvidia-persistenced.service # 查看服务是否正在运行
Docker 容器掉 Nvidia 驱动问题
每当运行 systemctl daemon-reload,挂载了 GPU 的 docker 容器便无法访问 GPU,会报错:
自 Docker 20.10 开始,当 docker 检测到系统使用 systemd,并且 cgroup 版本为 v2 时(Ubuntu 21.10 起,系统默认使用 cgroup v2),Docker 默认会使用 systemd 作为其 cgroup driver:
而当执行 systemctl daemon-reload 时,正在运行容器的 GPU 挂载会出现错乱(而这个问题直到 2025 年还没修)。
要解决这个问题,可以在 /etc/docker/daemon.json 中添加如下一行,将 docker 的 cgroup driver 改为 cgroupfs:
修改后,需重启 docker,再运行 docker info 时若显示 Cgroup Driver: cgroupfs,即修改成功。
A100 机器风扇
ada-A100 的 A100 GPU 散热是靠两个 9000 rpm 的工业暴力扇在机箱尾部吸风。若那两个风扇没有正常工作,A100 GPU 温度就降不下来。如果发现 A100 温度不正常(无负载时 70℃+),或许是因为这两个风扇没有全力运转。请检查 fancontrol.service 有没有正常工作,并运行 sensors 检查 fan1 和 fan3 是否在以 9000+ RPM 运转。
如果没有,重启 fancontrol.service 服务。如果无法重启,且报错包含 Device path of hwmon5 has changed(hwmon5 最后一个数字或许不一样),运行 ls /sys/devices/platform/nct6775.656/hwmon/ 看是 hwmon 几,修改配置文件 /etc/fancontrol 中 hwmon5 为查到的那个。
Docker 相关
docker 清理
清理已退出且未命名的 containers
“未命名”是指用户未使用
--name参数为容器命名,其实这种容器是有 name 的,不过 name 是 docker 在命名空间中随机生成的而已。
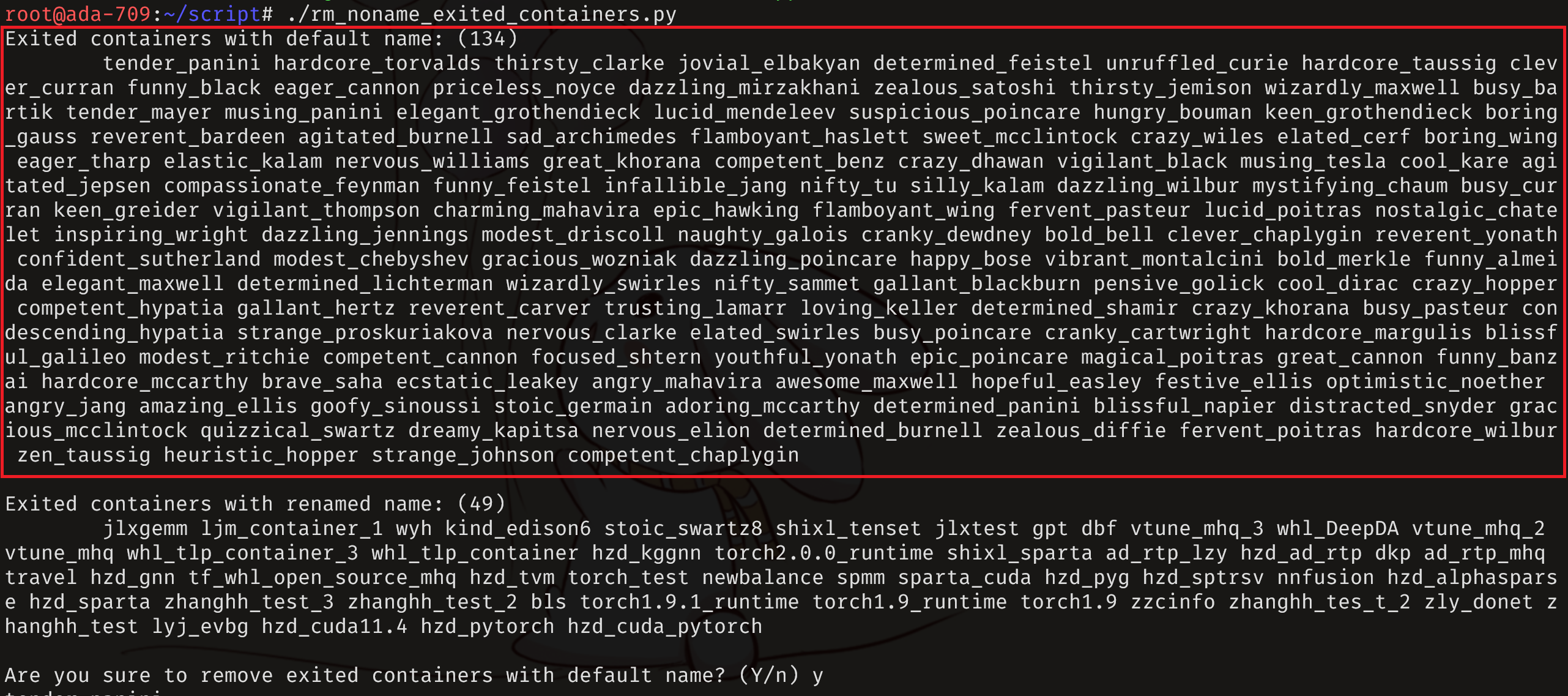
由于常有用户运行启动容器不添加 --rm 参数,且 docker build 失败后也会产生已退出且未命名的 container,所以导致一段时间后,服务器中会存在大量(上百个)退出但不再使用的容器。我们默认,若用户不给容器命名,那么他未来将不再会使用这个容器。因此管理员不定期可用脚本 /root/script/rm_noname_exited_containers.py 删掉退出且未命名的 container,运行示意如下所示,输入 y 或者直接回车,将删掉图中上半部分框出来的 134 个容器。而用户命名的容器即使状态已经变为 exited,即图中下半部分所示的 49 个容器,该脚本不会删除。
清理 dangling images
docker build 失败时会产生一些 tag 为 <none>:<none> 的 docker image。管理员发现时,可使用如下命令将这些 dangling images 删掉。
删除 dangling images:
或者(推荐)